Introduction
Apache Hive is a data warehousing tool used to perform queries and analyze structured data in Apache Hadoop. It uses a SQL-like language called HiveQL.
In this article, learn how to create a table in Hive and load data. We will also show you crucial HiveQL commands to display data.

Prerequisites
- A system running Linux
- A user account with sudo or root privileges
- Access to a terminal window/command line
- Working Hadoop installation
- Working Hive installation
Note: Follow our instructions for installing Hadoop and installing Hive on Ubuntu if you have not installed it before.
Create and Load Table in Hive
A table in Hive is a set of data that uses a schema to sort the data by given identifiers.
The general syntax for creating a table in Hive is:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT 'col_comment'],, ...)
[COMMENT 'table_comment']
[ROW FORMAT row_format]
[FIELDS TERMINATED BY char]
[STORED AS file_format];
Follow the steps below to create a table in Hive.
Step 1: Create a Database
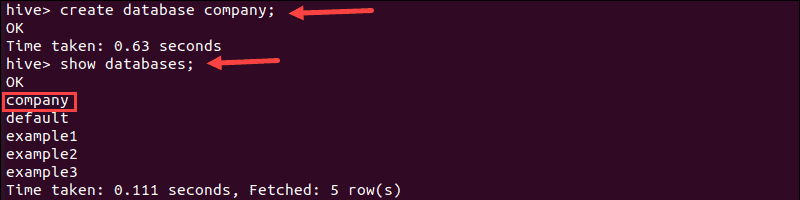
1. Create a database named “company” by running the create command:
create database company;The terminal prints a confirmation message and the time needed to perform the action.
2. Next, verify the database is created by running the show command:
show databases;3. Find the “company” database in the list:
4. Open the “company” database by using the following command:
use company;
Step 2: Create a Table in Hive
The “company” database does not contain any tables after initial creation. Let’s create a table whose identifiers will match the .txt file you want to transfer data from.
1. Create an “employees.txt” file in the /hdoop directory. The file shall contain data about employees:

2. Arrange the data from the “employees.txt” file in columns. The column names in our example are:
- ID
- Name
- Country
- Department
- Salary
3. Use column names when creating a table. Create the table by running the following command:
create table employees (id int, name string, country string, department string, salary int)4. Create a logical schema that arranges data from the .txt file to the corresponding columns. In the “employees.txt” file, data is separated by a '-'. To create a logical schema type:
row format delimited fields terminated by '-';The terminal prints out a confirmation message:

5. Verify if the table is created by running the show command:
show tables;
Step 3: Load Data From a File
You have created a table, but it is empty because data is not loaded from the “employees.txt” file located in the /hdoop directory.
1. Load data by running the load command:
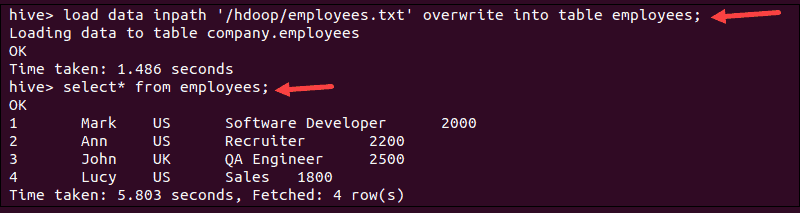
load data inpath '/hdoop/employees.txt' overwrite into table employees;2. Verify if the data is loaded by running the select command:
select * from employees;The terminal prints out data imported from the employees.txt file:
Display Hive Data
You have several options for displaying data from the table. By using the following options, you can manipulate large amounts of data more efficiently.
Display Columns
Display columns of a table by running the desc command:
desc employees;The output displays the names and properties of the columns:
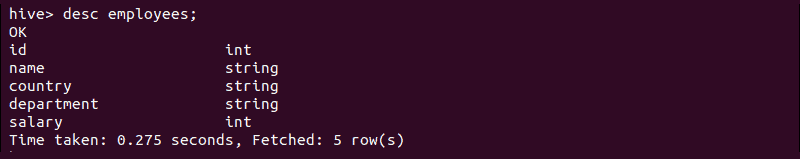
Display Selected Data
Let’s assume that you want to display employees and their countries of origin. Select and display data by running the select command:
select name,country from employees;The output contains the list of employees and their countries:

Conclusion
After reading this article, you should have learned how to create a table in Hive and load data into it.
There is also a method of creating an external table in Hive. In Hive terminology, external tables are tables not managed with Hive. Their purpose is to facilitate importing of data from an external file into the metastore.
Working in Hive and Hadoop is beneficial for manipulating big data. Next, we recommend our article about Hadoop architecture to learn more about how Hadoop functions.
